HTTPのバージョン
HTTP/0.9⇨HTTP/1.0⇨HTTP/1.1⇨HTTP/2
HTTP
HTTPは「クライアントサーバーモデル」を採用し、「複数のリソースの組み合わせ」を取り出せるプロトコル、TCP/IPがベースです
どういう意味???
クライアントサーバーモデル
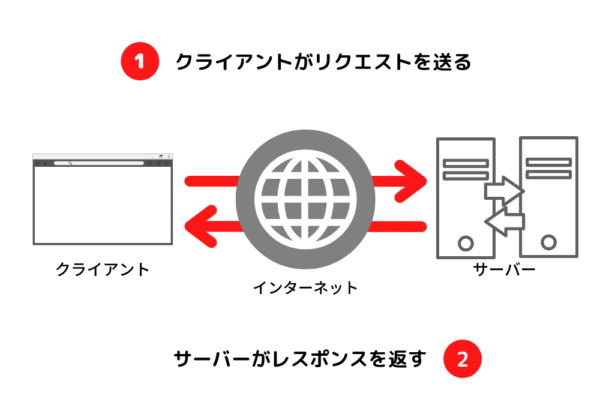
サービスを提供する側(サーバ)と、サービスを受ける側(クライアント)に役割が分かれるシステムです
HTTPでは
- クライアントは、サーバーにリクエスト(要求)を送信します
- サーバーは、リクエストを処理してクライアントにレスポンス(応答)を返します
- リクエスト
- クライアントが送信するメッセージ
- クライアントは、基本的にはWebブラウザです
- レスポンス
- Webサーバーが回答として送信するメッセージ
- ほとんどの場合、HTML・JSON・ XMLが含まれます
- Webサーバー
- HTTPにのっとり、HTMLや画像などを提供するためのソフトウェアをインストールしたコンピュータ
- ソフトウェアには「Apache」や「Nginx」があります
備考:レスポンス自体は文字列です
ブラウザがその文字列をパース(データを解析してプログラムで扱える構造にすること)して、画面にレンダリングしています
ターミナルなどからリクエストすると文字列のレスポンスが返ってきます
クライアントサーバーモデルとは?
クライアントがサーバーにリクエスト(要求)を送信し、サーバーがクライアントにレスポンス(応答)を返して処理されるネットワーク通信です
実際はブラウザとサーバーの間に「ルーターやモデムなどのコンピュータ」や「プロキシ」が存在します
主なプロキシの役割
- キャッシュ
- フィルタリング (ペアレンタルコントロールなど)
- 負荷分散
- 認証 (リソースへのアクセスを制御する)
- ログ記録
リソースとURI

- リソース
- ウェブ上に存在する名前を持ったありとあらゆる情報
- HTML・スタイルシート・スクリプト・画像などです
- URI
- リソースの名前(重複しない)
- リソースにアクセスするための住所の役割
- スキーム
- 通信の手段
- 「http」「https」以外では・FTPでファイルの送受信「ftp」・電子メール「mailto」など
- ホスト名
- サーバーの場所
- パス
- ファイルがある場所
- ユーザ情報
- サーバーからリソースを取得するのに必要な資格情報を指定
- ポート番号
- 通信するプログラムを識別するための番号
- クエリパラメータ
- サーバーに情報を送るためにつけたす文字列
- 「キー」と「値」の組み合わせ
- フラグメント
- ページをわける時に利用(ページ内のリンクなどで使う)
備考:URlで使用できる文字は「ASCII文字」です
ASCII文字は、半角の英字(a~z、A~Z)・アラビア数字(0~9)・半角記号などです
URlに日本語(ASCII文字以外の文字)を使う時は、「%エンコーディング」します
備考:URlとは全く関係のないことですがw
「リクエストやレスポンス」の中身は「文字列」です
画像や動画といった「バイナリファイル(テキストファイル以外のファイル)」はどうやって通信するのでしょうか?
「Base64エンコード」を利用して画像や動画を 「文字列」 へ
「Base64デコード」を利用してて「文字列」を 画像や動画に変換します
TCP/IP
ネットワークは階層構造で設計されています
HTTPはアプリケーション層(階層の一番上)に存在し、データのやり取りの仕組みは、下の階層のTCP/IPが担当します

- IP
- IPアドレスをもとに、パケット(分割したデータ)を宛先まで届けるためのプロトコル
- TCP
- 届いたことを確認しながら送信する、信頼性を保証するプロトコル
- UDP
- とりあえずデータを送りまくる速度重視のプロトコル
リクエストを送信するには、コネクションの確立が必要です(TCPの上にのっているためです)
TCPでは、クライアントは、サーバーにデータを送信することを先に通知します
そして、サーバーからの応答を確認し、テータを送信します (時間より信頼性が重視されます)
クライアントサーバーモデルは「1つのリクエスト」に対して「1つのレスポンス」です
ブラウザは「最初のレスポンス」を解析し、含まれているリンクのリクエストを送信します
全てのレスポンスがあつまると、ブラウザはHTMLをレンダリングして画面に表示します(リクエストが多くなると読み込みに時間がかかります)
HTTP/2では、1回のコネクションで複数のリクエストとレスポンスの処理ができ、リクエストを減らす対策は不要になりました
HTTP/3はUDPの上にのるそうです(UDPは時間重視です、サーバーからの応答待たずにデータを送りまくります)
今後、コネクションの確立が不要に・・・
HTTPの進化 😊
複数のリソースの組み合わせを取り出せるプロトコル、TCP/IPがベースとは?
TCPを使い、必要なHTML・スタイルシート・スクリプト・画像などを取得し、ページが表示されるための決まり事のことです
HTTPメッセージ
「クライアント」「サーバー」間での「メッセージ」のやりとりで、さまざまな機能を実現しています
- クライアントからサーバーに送る「リクエストメッセージ」
- サーバーからクライアントに送る「レスポンスメッセージ」
構造は「ライン」「ヘッダ」「空白」「ボディ」です
ウェブページを閲覧する時など、もっとも頻繁に利用する「GETメソッド」でリクエストしたときの、「リクエストメッセージ」と「レスポンスメッセージ」です
*メソッドについては、別のところで詳しく
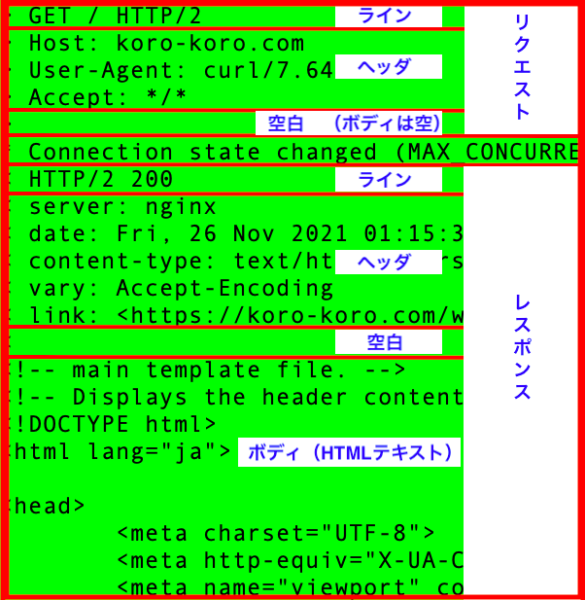
- 「ライン」
- 「ヘッダ」
- 「空行」
ヘッダの終了を空行で識別します - 「ボディ(本文)」
ボディがない場合もあります
ターミナルから「cURLコマンド」を使いました
*「cURLコマンド」もクライアントです
cURL(カール)は、さまざまなプロトコルを用いてデータを転送するライブラリとコマンドラインツールを提供するプロジェクトである。
https://ja.wikipedia.org/wiki/CURL
HTTPヘッダーを確認できます
curl -v サイトのURL リクエストメソッド
メソッドはサーバーへの指示です
「GET」「POST」「PUT」「DELETE」「HEAD」「OPTIONS」「TRACE」「CONNECT」の計8個です
代表的な4つのメソッドです
基本の機能を表す「CRUD」は、記事に例えると、記事の新規作成、記事の表示、記事の更新、記事の削除のイメージです
- POST
- リソースの作成、リソースへのデータの追加、 他のメソッドで対応できない場合
- Create(作成)
- GET
- URI情報の取得です、ウェブページをみる時など利用頻度の高いメソッドです
リソースの状態は変化しません - Read(読み込み)
- PUT
- リソースの更新、リソースの作成(べき等です:べき等とはある操作を1回行っても複数回行っても結果が同じ)
- Update(更新)
- DELETE
- 削除 (べき等です)
- Delete(削除)
HTMLのフォーム(form)で利用できるのは「GET」と「POST」だけです
- GET
- URLの末尾にパラメータをくっつけて送る方法
検索キーワードなどに使います - 文字数に制限があります
- POST
- レクエストボディ(本文)でパラメータを送る方法
- ブックマークができません
XMLHttpRequest APIやFetch API(フロントエンドのJavaScript)では、「GET」「POST」以外のメソッドが使用できます(配信するフォーマットは、ほぼJavaScriptから利用しやすい「JSON形式」です)
備考:処理ごとにURLのパスを準備するのではなくリソース毎にパスを準備して同じパスのメソッドを切り替える(REST API)
ステータスコード
レクエストの結果を、レスポンスラインで知らせます
ステータスコードは3桁の数字で、先頭の数字で大きく5つに分類されます
- 1・・処理中
- 100 Continue リクエストを継続できる
- 2・・成功
- 200 OK リクエスト成功
201 Created リソース作成成功
- 3・・リダイレクト
- 301 Moved Permanently 恒久的な移動(移転した場合)
302 Found 一時的な移動
- 4・・クライアント側のエラー
- 400 Bad Request クライアントのリクエストがおかしい場合
401 Unauthorized 認証が必要(Basic認証行うときに使用される)
*WWW-Authenticateで認証方式が指定されていれば、認証ダイアログが表示されます
403 Forbidden アクセス権がない場合など、アクセスが拒否されたとき
404 Not Found ページが見つからない
- 5・・サーバー側のエラー
- 500 Internal Server Error サーバー内部にエラーが発生
502 Bad Gateway プロキシサーバーが拒否
ヘッダ
ヘッダは、「一般」「エンティティ」「リクエスト」「レスポンス」に分類され、多数あります
クライアントとサーバーで合意すれば、「新たなヘッダ」を導入できます
一般
リクエスト・レスポンス両方に適用されます
- Cache-Control
- クライアント側でのキャッシュに関する動作を規定
- 例 no-cache
- Connection
- 接続を維持するかどうかを指定
- 例 keep-alive(接続を維持)
- Date
- 生成した日時
エンティティ
リクエスト・レスポンス両方に適用されます(ボディに関すること)
- Allow
- リソースがサポートするHTTPメソッド
- Content-Encoding
- リソースのエンコーディング方式
- Content-Length
- リソースの長さ(単位はバイト)
- Content-Type
- MIMEタイプを指定
- 例
text/html; charset=UTF-8
application/json(JSON 形式)
application/x-www-form-urlencoded(フォームの送信時)
- Expires
- リソースの有効期限
- Last-Modified
- リソースの最終更新日時
リクエストヘッダ
- Accept
- クライアントが処理できるメディアタイプを伝えます
- Authorization
- ブラウザがサーバーから認証を受けるための証明書を保持し、基本的にはサーバーが 401Unauthorized ステータスとWWW-Authenticateヘッダを返した後に使われます
- Cookie
- クライアントに保存されたクッキー情報
- Host
- 要求先ホスト名
- if-Modified-Since
- 指定日時より後に変更された場合のみ返却するよう要求
- Referer
- 別のページに遷移したときの遷移元のページ
- User-Agent
- クライアント情報
レスポンスヘッダ
- Accept-Ranges
- サーバーが部分的なリクエストに対応していることを知らせるマーカー
- Etag
- リソースを一意に特定するための情報
- Location
- クライアントを指定したURIへリダイレクトさせます
- Server
- サーバーの種類
- Set-Cookie
- サーバーからクライアントへ送信するクッキー情報
Cookie
「ファーストパーティCookie」とサードパーティCookie
閲覧しているページで発行される「Cookie」を「ファーストパーティCookie」といいます
閲覧ページ以外でも、広告バナーなど異なるドメインの「サードパーティCookie」が設定されることがあります
「サードパーティCookie」の目的はトラッキング(ユーザーの情報を取得するために、ユーザーの行動を追跡・分析することです)です
セッション管理
HTTPはステートレスです
ステートレスとは、状態を保持しないことです
「ステートレス」なので、サーバーはクライアントとのやり取りを覚えていません
では、サーバーが覚えていなければ、「ショッピングカートの中身は消える?」「ページがかわるたびにログインが必要?」
「ショッピングカートの実装」や「ログイン済みの認可」は可能です
リクエストとレスポンスのヘッダを利用し「Cookie」をやり取りすることで、
セッションを管理します
セッション管理とは、相手や相手の状態を覚えておくことです
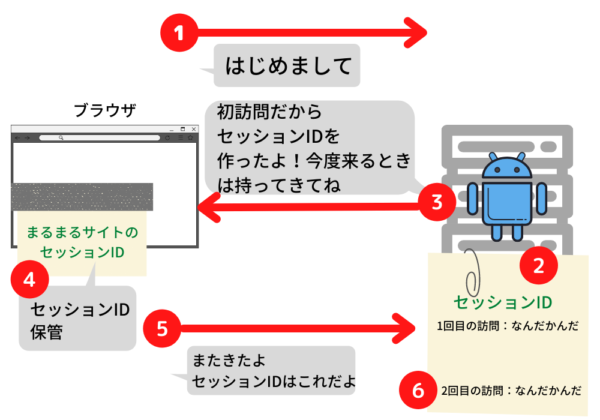
サーバーはユーザーごとに「Cookie」をセッションID(整理番号の役割です)として発行して、ユーザー情報を管理します
ブラウザは「このCookie」を「ヘッダ」につけて送り、サーバーはセッションIDを照合し、セッション管理をします
余談HTTP認証(HTTPでサポートされている認証機能)には、Basic認証、NTLM認証、Digest認証などがあります
ユーザが、ID・パスワードを入力するのは1回です
しかし、リクエストのたびにブラウザが「Authorizationヘッダ」をつけ、リクエストのたびにID・パスワードを送信しています
HTTP認証は、Cookieによるセッション管理とはちがい、ステートレスです
CSRF攻撃
脆弱性を狙った攻撃・CSRF(クロスサイトリクエストフォージェリ)
攻撃対象サイトにログイン済みのユーザーに、悪意のあるサイトをクリックさせ、意図しない処理を実行させる脆弱性です
ブラウザのクッキーに保管さたセッションIDは、対象サイトに自動で送信される性質が悪用されます
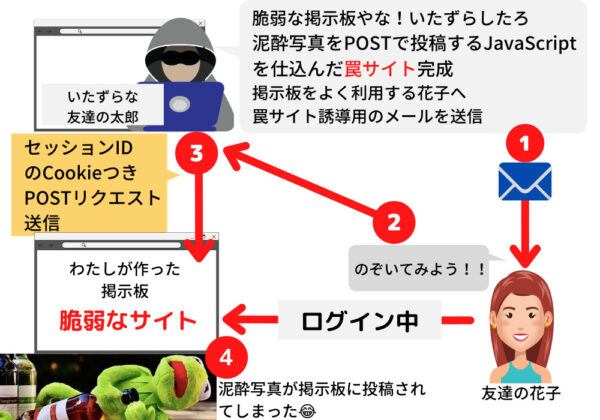
POSTの送信先はどのドメインでも指定できます(*画像はXMLHttpRequestやFetchで送れます、またCORSはリクエスを送るだけなら問題になりません、レスポンスを受け取るときのブラウザ側のセキュリティ機能です)
罠サイトをひらいた瞬間に、ヘッダにCookie付きのリクエストが送信され、リクエストが処理されます(泥酔写真が投稿されます^^;)
対策方法の1つは、トークンを利用して「正しいサイトからのリクエストか?」をチェックします
HTMLのinput type="hidden"にトークン埋め込み、送信されたトークンとセッションに保存しているトークンの値が一致すれば「正しいサイトからのリクエスト」と判断できます
トークンがないリクエストはブロックします
その他備忘録
CORSとContent-Typeの関係について
CORSは、あるオリジン(例えば、http://localhost:3000)で実行されているウェブアプリケーションが、異なるオリジン(例えば、https://script.google.com)のリソースにアクセスする際のブラウザのセキュリティメカニズムです
同一オリジンポリシーにより、異なるオリジン間のリクエストは基本的にブロックされますが、CORSは特定の条件下でこの制限を緩和します
Content-Type と非シンプルリクエスト
CORSの文脈での「シンプルリクエスト」とは、特定の安全なメソッド(GET、HEAD、POST)を使用し、特定のヘッダーのみを設定しているリクエストを指します。
シンプルリクエストでは、以下の Content-Type の値が許可されます
text/plain
multipart/form-data
application/x-www-form-urlencoded
これらのContent-Typeを持つリクエストは、追加のCORSヘッダーなしで送信できます
しかし、application/json という Content-Type はシンプルリクエストの条件に含まれていません
そのため、JSONデータを送信する場合は「非シンプルリクエスト」(プリフライトリクエストが必要なリクエスト)となり、CORSポリシーによる制限を受けるために、サーバー側で適切なCORSヘッダーの設定が必要になります
*サードパーティAPIを利用する場合は、ほぼ該当します
レスポンスは文字列
レスポンスは文字列なので、プログラムで扱うには「パース」が必要です
プログラムで扱えるようなデータ構造の集合体に変換することをパースといい
そのためのプログラムなどのことを「パーサ」といいます
余談 ターミナルがどぎつい緑の理由です😅