Puppeteerを使わないスクレイピング

Puppeteerに関してはこの続き

Puppeteerでブラウザを操作してスクレイピングします
*最終的にGoogle検索をコマンドで実行、検索結果(タイトルとURL)を書き出したファイルをデスクトップに保存します
PuppeteerでXPathを使う
XPathはセレクタ(document.querySelectorAll)で指定するより便利な気がします
(子要素で特定してからその親要素を指定したりができます^^;)
Chomeの開発者ツールでElementタブで「Command(Ctrl)+ F」で検索欄を表示
XPathを入力して要素数や右横の上下アイコンをクリックして要素を確認できるので便利です
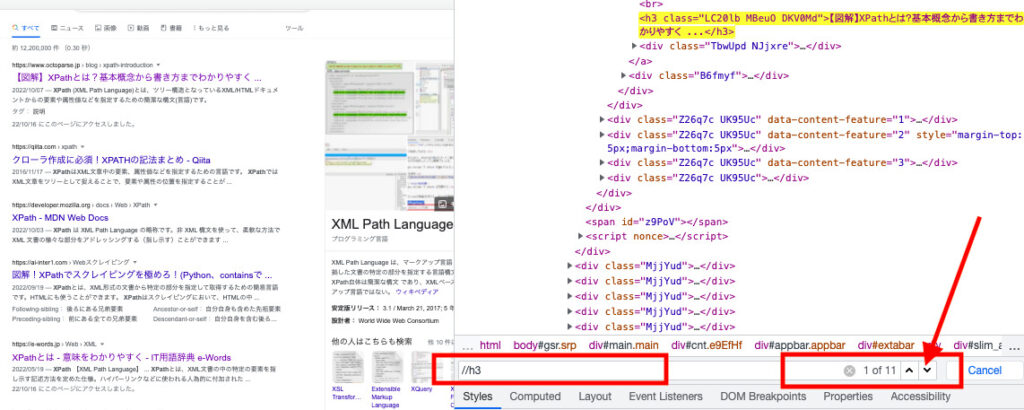
Googleで「XPath」を検索した時の結果から「タイトルとURL」を取得してみます
タイトルを取得します
*page.$x() メソッドはXPath式を評価しDOM要素(ElementHandleオブジェクト)の配列を返します
要素がない場合は空の配列を返します
*ElementHandle.getProperty(propertyName):オブジェクトからプロパティを取得してJSHandleオブジェクト返します
*JSHandle.jsonValue():値を取り出します
注意:どちらも返り値はPromiseです
import puppeteer from "puppeteer";
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(
"https://www.google.com/search?q=xpath"
);
const xpath = "//h3[contains(@class,'LC20lb')]"
//取得するまで待機
await page.waitForXPath(xpath);
const elementHandleList = await page.$x(xpath);
//タイトルを取得
const titles = await Promise.all(
elementHandleList.map(
async (el) => await (await el.getProperty("textContent")).jsonValue()
)
);
//Promiseが返されるのでコールバックだと非同期の扱いがややこしい!!
//forループで書くと
// const elementHandleList = await page.$x(xpath);
// const titles =[]
// for (let i = 0; i < elementHandleList.length; i++) {
// const prop = await elementHandleList[i].getProperty("textContent");
// titles.push(await prop.jsonValue());
// }
console.log(titles);
await browser.close();
})();
// [
// "【図解】XPathとは?基本概念から書き方までわかりやすく ...",
// "クローラ作成に必須!XPATHの記法まとめ - Qiita",
// "XPath - MDN Web Docs",
// 省略
// ];コードを整理して(関数にして)タイトルとリンクをせれぞれ取得します
*関数にする場合の備忘録として
import puppeteer from "puppeteer";
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(
"https://www.google.com/search?q=xpath"
);
//xpathからDOM要素(ElementHandle)オブジェクトの配列を取得する関数
const getElements = async (xpath) => {
await page.waitForXPath(xpath);
return await page.$x(xpath);
};
//個々のDOM要素から値を取り出す関数
const getProperty = async (elementHandle, property) => {
return await (await elementHandle.getProperty(property)).jsonValue();
};
//タイトルのリスト
const h3Els = await getElements("//h3[contains(@class,'LC20lb')]");
const titles = await Promise.all(
h3Els.map(async (el) => await getProperty(el, "textContent"))
);
//リンクのリスト
const aEls = await getElements("//h3[contains(@class,'LC20lb')]/parent::a");
const links = await Promise.all(
aEls.map(async (el) => await getProperty(el, "href"))
);
//タイトルとリンクの配列の値を結合して作成したオブジェクトの配列にします
const result = titles.map((title, index) => ({
title: title,
link: links[index],
}));
console.log(result);
await browser.close();
})();
// [
// {
// title: '【図解】XPathとは?基本概念から書き方までわかりやすく ...',
// link: 'https://www.octoparse.jp/blog/xpath-introduction/'
// },
// {
// title: 'クローラ作成に必須!XPATHの記法まとめ - Qiita',
// link: 'https://qiita.com/rllllho/items/cb1187cec0fb17fc650a'
// },
// 省略
// }$x(XPath)を使うとオブジェクトからプロパティを取得してそれを文字列として扱えるようにするのがややこしいです
また、それぞれに取得するとまとめるにも手間もかかります
そこで
XPathでElementHandleオブジェクトの配列を取得し$eval()で値を取り出すパターン
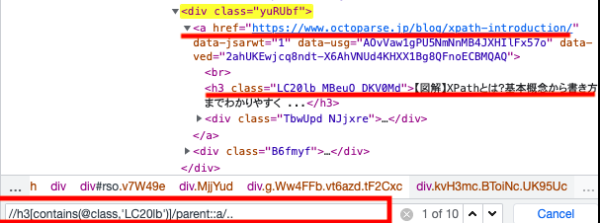
*対象の階層の一つ上までをXPathで取得して、個々のElementHandleオブジェクトに対して$eval()で値を取り出します
*$eval(セレクタ, callback)はdocument.querySelectorを実行して、結果を第二引数の関数の引数に渡します
最初に階層を絞っているのでセレクタの選択がシンプルです
import puppeteer from "puppeteer";
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(
"https://www.google.com/search?q=xpath"
);
const xpath = "//h3[contains(@class,'LC20lb')]/parent::a/..";
await page.waitForXPath(xpath);
const elementHandleList = await page.$x(xpath);
const results = []
for (let el of elementHandleList) {
let title = await el.$eval("h3", (el) => el.textContent);
let link = await el.$eval("a", (el) => el.getAttribute('href'));
results.push({
title,
link
})
}
console.log(results);
await browser.close();
})();XPathについて
XPathとはXML/HTMLドキュメントの中の特定の要素を指し示す記述方法です
ツリー構造のように頂点となるルートノードを「/」で表し要素名や一致条件などを「/」で区切って順番に指定していきます(/html/body/h1)
*「//」を使用して途中までのパスを省略できます
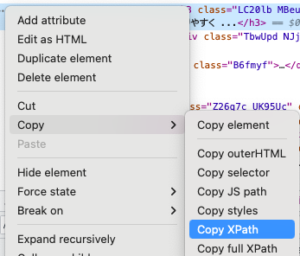
Chomeの開発者ツールElementタブのhtmlの要素を右クリックしてメニューの「Copy」 → 「Copy XPath 」でその要素のXPathがクリップボードにコピーされます
XPathの書き方
タグ名で区切って順番に指定
- 子要素://基点要素のタグ名/子要素のタグ名
- 子孫要素://基点要素のタグ名//子孫要素のタグ名
- 親要素://基点要素のタグ名/..
タグに述語(条件)をつける://タグ名[一致条件]
- タグ名
- タグだけの場合://タグ名
タグに述語(一致条件)をつける://タグ名[] - 例:
//h2:すべてのh2要素
例://h2[2]:2番目のh2要素
- 属性(href、title、style、srcなど)で選択
- タグ名[@属性名=’属性値’]
- 例:
//p[@class='hoge']:class名がhogeのp要素
*class名にhogeが含めれるp要素ではないことに注意
*//p[@class='hoge hoge2']:マルチクラス
例://*[@class='hoge']:class名がhogeのすべての要素
- text()
- テキストを取得
- 例:
//h3[text()='説明']:テキストが説明のh3要素
- contains()
- 属性値やテキスト指定した文字列が含まれているか検索
- 例:
//p[contains(@class, 'hoge')]:class名にhogeが含まれるp要素
- starts-with()
- 先頭のテキストを検索
- 例:
//a[starts-with(@href, 'https')]:httpsで始まるa要素
- position()
- 要素を位置指定
- 例:
//tr/td[position()=2]://tr/td[2]と同じですが[position()>2](3番目から)のように指定できます
- not・and・or
- not():条件を含まない要素
and:条件全てに一致する要素
or:いずれかの条件に一致する要素 - 例:
//a[not(contains(@href, 'pdf'))]:hrefにpdfを含まないa要素
例://img[contains(@src,'png') and contains(@class,'hoge')]:classにhogeかつsrcにpngを含むimg要素
例:*//img[not(contains(@src,'png') or contains(@src,'jpg'))]:pngかjpg以外のimg要素
ツリー上の位置関係(軸)を指定してHTMLマークアップを上や同階層の別の要素に移動
- parent::node()
- 親を指定
*node()はどの要素でも取得するためでタグ名を指定することもできます - 例:
//p[@id="hoge"]/parent::node():idがhogeのp要素の親要素
- ancestor::node()
- 祖先を指定
- 例:
//p[@id="hoge"]/ancestor::node():idがhogeのp要素の祖先(親も含む)を指定
- preceding-sibling::前の兄弟要素のタグ名
- 前にある兄弟要素を指定
- following-sibling::後の兄弟要素のタグ名
- 後にある兄弟要素を指定
- 例:
//th[text()="備考"]/following-sibling::td[1]
ページ遷移
とりあえずページ遷移を確認してみますlaunch({ headless: false })でブラウザが立ち上がります
ElementHandleオブジェクトからclick()の操作ができますpage.waitForNavigation():新しいURLを開いた後、リロード後ページが読み込まれるのを待ちます

import puppeteer from "puppeteer";
(async () => {
// { headless:false }オプションでUIを表示
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto("https://www.google.com/search?q=xpath");
//次へのaタグ要素(配列で取得されます)
const nextPageHandleList = await page.$x("//span[text()='次へ']/parent::a");
await Promise.all([
page.waitForNavigation(),
nextPageHandleList[0].click(),
]);
//確認のため2秒待機
await new Promise((r) => setTimeout(r, 2000));
await browser.close();
})();検索キーワードとページ数を指定して情報を取得します
取得した情報はJson形式でファイルに保存します
import puppeteer from "puppeteer";
import fs from "fs/promises";
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
const results = [];
//結果を取得する関数
const getResult = async () => {
const xpath = "//h3[contains(@class,'LC20lb')]/parent::a/..";
await page.waitForXPath(xpath);
const elementHandleList = await page.$x(xpath);
for (let el of elementHandleList) {
let title = await el.$eval("h3", (el) => el.textContent);
let link = await el.$eval("a", (el) => el.getAttribute("href"));
results.push({
title,
link,
});
}
};
//ページ遷移する関数
const goToPage = async () => {
const nextPageHandleList = await page.$x("//span[text()='次へ']/parent::a");
if (nextPageHandleList.length === 0) return;
await Promise.all([
page.waitForNavigation(),
nextPageHandleList[0].click(),
]);
await new Promise((r) => setTimeout(r, 100));
};
//検索キーワードとページ数を引数に
const getAllResult = async (keyword, max) => {
await page.goto(`https://www.google.com/search?q=${keyword}`);
await getResult();
let i = 1;
while (i < max) {
await goToPage();
await getResult();
i++;
}
console.log(results);
};
//getAllResult(検索キーワード,ページ数)関数を呼び出す
await getAllResult("xpath", 2);
//Json形式で保存する
const textJson = JSON.stringify(results, null, "t");
await fs.writeFile("result.json", textJson, "utf8");
await browser.close();
})();エラー処理について
page.waitFor…を使っている場合
自動化していた場合など、サイトのマークアップが変更されていた場合は注意が必要ですtry..catch..finallyで対応した場合でもpage.waitFor...は「セレクタやXpathが見つかるまで待つ」ためブラウザが開いたままになります
(async () => {
const data =[]
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
try {
await page.goto("https:/");
const xpath = "//div・・・・";
const elementHandleList = await page.$x(xpath);
//もしxpathがない場合 page.waitForXPathのためブラウザが閉じない
if (elementHandleList && elementHandleList.length !== 0) {
await page.waitForXPath(xpath);
//処理
}
} catch (e) {
console.log("エラー");
} finally {
//正常処理・エラーどちらでもブラウザを閉じる
await browser.close();
}
})()Google検索をコマンドで実行
ターミナルで「google 検索キーワード ページ数」で実行するとデスクトップに結果のファイルが保存されるようにします
//コマンドの引数を受け取る
const keyWord = process.argv[2]
const max = process.argv[3];
await getAllResult(keyWord, max);
const textJson = JSON.stringify(results, null, "t");
await fs.writeFile(
//デスクトップまでの絶対パス
"/Users/hoge/Desktop/result.json",
textJson,
"utf8"
);*Firefoxをインストールしていれば、保存するファイルの拡張子を「.json」にするとURLをクリックしてページを開くことができます
エイリアス(コマンドに「別名をつけて」入力を簡素化)を設定ファイル(シェルがbashなら.bashrc・zshなら.zprofile)に書き込みます
ちなみに複数のコマンドを連続して実行する場合
コマンド1 && コマンド2 でコマンド1正常終了した場合のみコマンド2が実行されます
echo "alias google='node プロジェクトフォルダまでの絶対パス/index.js'" >> ~/.bashrc
source ~/.bashrce
#検索する時
google "検索キーワード" ページ数