node-fetch
Node.jsアプリでPromiseベースのHTTP通信を行うためのライブラリです
npm i node-fetchhtmlファイルとして取得(レスポンスを文字列で取得)
*プロジェクトフォルダの下にoutputフォルダを作成
import fs from 'fs/promises';
import fetch from 'node-fetch';
(async () => {
try {
const response = await fetch('対象サイトのURL');
// 文字列を取得
const html = await response.text();
// ファイルの保存
await fs.writeFile('./output/index.html', html, 'utf8');
} catch(error) {
console.log(error);
}
})();画像などのバイナリファイルを取得
import fs from 'fs/promises';
import fetch from 'node-fetch';
const imageUrl = '画像のURL'
// 末尾を取得してファイル名に
const fileName = imageUrl.split('/').pop();
(async () => {
try {
const response = await fetch(imageUrl);
const arrayBuffer = await response.arrayBuffer();
const buffer = new Buffer.from(arrayBuffer);
await fs.writeFile(`./output/${fileName}`, buffer);
} catch(error) {
console.log(error);
}
})();splitで情報を取得
文字列から必要な情報を取得します
split(文字列)メソッドは文字列を「引数の文字列」で分割して配列に格納しますslice(開始インデックス[, 終了インデックス])メソッドは「文字列や配列」を切り抜くことができます
文字列.indexOf(検索対象の文字列)
文字列が見つかった場所(0以上)
文字列が見つからなければ「-1」が返ります
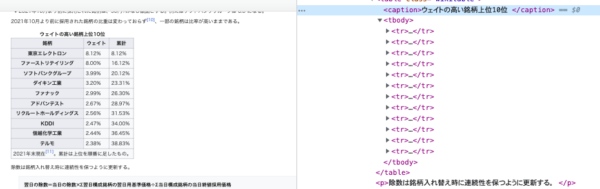
シンプルなテーブルの情報を取得しますslice()を使ってテーブル部分のhtml文字列を切り抜きsplit()を使って「</tr>」で分割して配列にします
import fetch from 'node-fetch';
import fs from 'fs/promises';
(async () => {
try {
const response = await fetch('https://ja.wikipedia.org/wiki/%E6%97%A5%E7%B5%8C%E5%B9%B3%E5%9D%87%E6%A0%AA%E4%BE%A1#%E6%A7%8B%E6%88%90%E9%8A%98%E6%9F%84%E4%B8%80%E8%A6%A7');
// 文字列を取得
const html = await response.text();
//対象テーブル周辺の文字列(ページ内で一意のもの)から位置を取得
const first = html.indexOf('>ウェイトの高い銘柄上位10位')
const last = html.indexOf('>除数は銘柄入れ替え時に連続性を保つように更新する。')
//対象テーブルの周辺に絞る
const target = html.slice(first, last)
//</tr>で分割し配列を作成
const list = target.split('</tr>')
//*必要な要素のみの配列にする為に最後の要素を確認
//console.log(list[list.length-1])
const targetList = list.slice(1, list.length - 2)
//1行分を<td>で分割して配列にしたときの要素数
const tdCount = targetList[0].split('<td>').length
const result = targetList.map(item => {
//</th>があれば
let obj ={}
if(item.indexOf('<th>') != -1){
obj = {
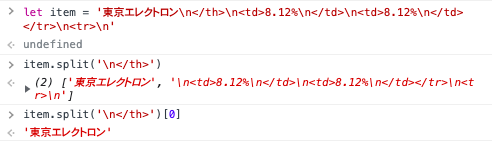
th: item.split('<th>')[1].split('n</th>')[0]
}
}
//<td>のループを調整する
for (let i = 1; i < tdCount; i++) {
//objのkey
let key = `td${i}`
let str = item.split('<td>')[i]
//console.log(str)
//状況に応じ、strを確認して調整
if(str.indexOf('n</td>') != -1){
obj = {...obj, [key]:str.split('n</td>')[0]}
}else{
obj = {...obj, [key]:''}
}
}
return obj
})
console.log(result)
//Json形式で保存する(タブ文字で標準的な整形)
const textJson = JSON.stringify(result, null, 't');
await fs.writeFile('./output/result.txt', textJson, 'utf8');
} catch(error) {
console.log(error);
}
})();
// [
// { th: '東京エレクトロン', td1: '8.12%', td2: '8.12%' },
// { th: 'ファーストリテイリング', td1: '8.00%', td2: '16.12%' },
// 省略
// ]文字列から必要な情報だけ取得
split(文字列)で配列にして、[index]を指定して1つの要素に絞ります
これを繰り返し必要な情報を取得します
jsdom
「jsdom」を使うとブラウザと同じようにDom APIを操作できます
npm i jsdomimport fetch from 'node-fetch';
import jsdom from 'jsdom';
const { JSDOM } = jsdom;
(async () => {
try {
//html取得
const response = await fetch('サイトのURL');
const html = await response.text();
//パース
const dom = new JSDOM(html);
const document = dom.window.document;
} catch(error) {
console.log(error);
}
})();例えば
「document.querySelectorAll(セレクター)」 でNodeList を取得して「Array.from」で配列にします
要素から必要な情報を取得します
- 要素.outerHTML : 外部HTMLの文字列
- 要素.innerHTML :内部HTMLの文字列
- 要素.textContent :内部テキスト
- 要素.value :フォームの値
- 要素.プロパティ名 : プロパティの値
主な配列のメソッド
| メソッド | 説明 | 戻り値 |
| forEach | 配列の各要素に対して関数を1つずつ実行 | undefined |
| map | 関数の結果から新しい配列を作成 | 新しい配列 |
| filter | 関数でtrueを返した要素のシャローコピーを作成 | シャローコピー(同じ参照を共有する) なければ空の配列 |
| find | テスト関数を満たす配列内の最初の要素 | 関数を満たす最初の要素 なければundefined |
| every | 関数がすべての要素について真値を返した場合にtrue | true/false |
| concat | 2つ以上の配列を結合 | 新しい配列 |
| reduce | 直前の要素における計算結果の返値を渡して集約します 初回は「直前の計算の返値」は存在しませんが、第二引数で初期値を設定できます | 最終結果(単一の値) |
Wikipediaのトップページから画像のURLを取得してみます
import fetch from 'node-fetch';
import jsdom from 'jsdom';
const { JSDOM } = jsdom;
(async () => {
try {
//html取得
const response = await fetch('https://ja.wikipedia.org/wiki/%E3%83%A1%E3%82%A4%E3%83%B3%E3%83%9A%E3%83%BC%E3%82%B8');
const html = await response.text();
//パース
const dom = new JSDOM(html);
const document = dom.window.document;
//要素の配列かれ必要な情報の配列にします
const imgUrl = Array.from(document.querySelectorAll('img'))
.map(el => el.src)
.filter(el => el.indexOf('.svg.png') === -1 && el.indexOf('//upload.wikimedia.org')!== -1)
.map(el => `https:${el}`)
console.log(imgUrl)
} catch(error) {
console.log(error);
}
})();備考(便利な関数)
配列を文字列にしたいときはreduceが便利
*innerHtmlを作成するときなど
const items = ['apple', 'orange', 'banana']
const li = items.reduce((accu, item) => {
return accu + `<li>${item}</li>`
}, '')
console.log(li)
//<li>apple</li><li>orange</li><li>banana</li>Robots.txt
Robots.txtは、クロールの制御情報が書かれているファイルです
サイトのドメインのルートディレクトリにあります
http://hoge.com/robots.txt
- User-Agent:クローラーの種類
- Disallow:Disallowで指定されたファイルやディレクトリはクロール禁止です