
OpenAIのAPIを通じてGPT(Generative Pretrained Transformer)を利用することができます
OpenAIのAPIを使うための準備
OpenAIのAPIを使うためにはAPIキーが必要です。
OpenAIのAPIの利用は有料です。
現在の利用料はこちらのページで確認可能
https://platform.openai.com/account/usage
利用料の上限(リミット)を設定することも可能です。
私自身、このAPIをテストしてますが、まだ1ドルも請求されていません。
次に、プログラミング言語でAPIを呼び出すためのパッケージをインストールする必要があります。Pythonの場合、openaiという名前のパッケージをインストールします。
!pip install openai
私は、Jupyter Notebookを使いました。
Jupyter Notebookは、コードの実行結果を直接確認しながら逐次的にプログラムを記述できる対話型の開発環境です。Pythonをはじめとする様々なプログラミング言語をサポートしており、設定も簡単で直感的です。
GPTに指示を送り、結果を表示します
import openai
# APIキーの設定
openai.api_key = 'ここにAPIキー'
# APIの呼び出し
response = openai.Completion.create(
model="text-davinci-003",
prompt="フランス語でこんにちは",
max_tokens=100
)
# 結果の表示
print(response.choices[0].text.strip())レスポンスはこんな感じ

APIキーをコードから分離
公開する可能性のあるコードにAPIキーをハードコードするのはリスクがあります。
python-dotenvパッケージを使ってAPIキーを管理する方法で、APIキーをコードから分離し、安全に保管することが可能となります。
!pip install python-dotenvプロジェクトのルートディレクトリに「.envファイル」を作成します。
そのファイルにAPIキーを記述します。
OPENAI_API_KEY=ここにAPIキー
*.envファイルは、公開しないように注意する必要があります。GitHubなどのバージョン管理システムを使用している場合は、.envファイルを.gitignoreに追加して公開を防ぐことができます
dotenvパッケージを使ってAPIキーをロードします
from dotenv import dotenv_values
config = dotenv_values(".env")
openai.api_key = config["OPENAI_API_KEY"]主なパラメーター
一覧
engine: 使用するエンジンを指定します。例: ‘text-davinci-002’、’text-curie-002’など。prompt: AIに入力するテキスト。AIはこのテキストに基づいて出力を生成します。max_tokens: AIが生成するテキストの最大トークン数を指定します。temperature: 出力のランダム性(創造性)を制御します。高い値(例:1.0)はよりランダムな出力を、低い値(例:0.2)はより決定論的な出力を生成します。
デフォルトは1です。top_p: temperatureと同様に出力のランダム性を制御しますが、具体的にはトークンが出力される確率を制御します。これは”nucleus sampling”とも呼ばれます。frequency_penaltyandpresence_penalty: 特定の語彙が出力にどれだけ現れるかを制御するためのパラメータです。model: モデルの種類を指定します。Chatモデルに特有のパラメータであり、例えば ‘gpt-3.5-turbo’ などを指定します。messages: Chatモデルのためのパラメータで、メッセージのリストを受け取ります。各メッセージは”role”(’system’、’user’、または’assistant’)と”content”(メッセージの内容)の2つのフィールドを持つオブジェクトです。use_cache: 過去のレスポンスをキャッシュして再利用するかどうかを制御します。デフォルトでTrueに設定されています。n: 一つのプロンプトから複数の異なる完全な出力を生成するためのパラメータです。例えば、5つの異なる文章を生成したい場合、nパラメータを5に設定します。stop: AIが特定の文字列を生成したら出力を停止するために使われます。たとえば、ある特定の文字列(例えば、”n”や特定の単語やフレーズ)が出力された時点で、生成を終了させたい場合などに使われます
エンジン(engine)について
OpenAIのAPIを使う際には、エンジンと呼ばれる特定のモデルを指定します。
それぞれ性能とコストの点で異なる特性を持っています
各タスクと予算により、適切なエンジンを選択します。
- Davinci: 最も強力だが最もコストが高い。複雑なタスクや抽象的な指示を理解するのに適しています。
- Curie: Davinciよりも低性能だが、多くのタスクを適切にこなすことができ、コストもそれほど高くない。
- Babbage: より一般的なタスクに適しており、コストもさらに低い。
- Ada: 最もコスト効率が良い。単純なタスクや大量のデータを扱う必要がある場合に適していますが、複雑なタスクには他のエンジンに比べて性能が低い可能性があります。
備考:「text-davinci-003」は2023年6月現在最新のテキストモデルで、このモデルは、高品質な文章作成、複雑な指示の処理、長い形式のコンテンツの生成などを可能にするように改善され、タスクにも対応できるようになっています
max_tokensについて
OpenAI APIのリクエスト時に設定するパラメータの一つで、AIが生成するテキストの長さを制御します。
一つの「トークン」は、言葉の一部または全体、または句読点を表します。
例えば、max_tokensを5に設定した場合、5トークンで切り捨てられ、それ以上の情報は得られません。
max_tokensの値が大きすぎると、生成するテキストが長くなりすぎ、またコストが高くなる可能性があります。
max_tokensは指定した数以下のトークンを出力しますが、それが最低限のトークン数を保証するわけではありません。
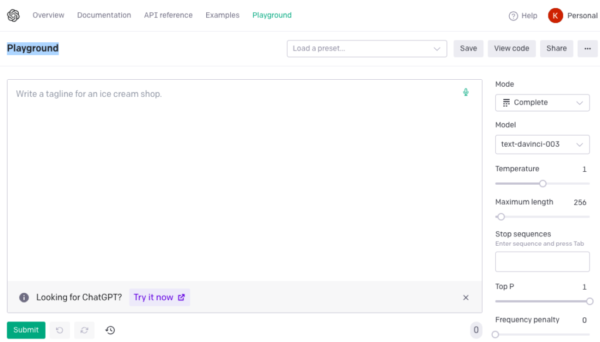
OpenAI Playgroundの利用方法
OpenAI Playgroundは、OpenAIのAPIを簡単に試せるオンラインの対話的なインターフェースです。
コードを書くことなくOpenAIのAPIを利用することができます。
エンジンの選択、プロンプトの入力、出力の閲覧などを直感的に行うことができます。
OpenAIの公式ウェブサイトにアクセスしてログイン→ダッシュボードにある「Playground」をクリックします
注意
APIの使用料はPlayground内での利用にも適用されます
CompletionsとChat
OpenAIのAPIには、「Completions API」と「Chat Completions API」という二つの主なタイプが存在します。
- Completions APIは、あるテキストフレーズの続きをAIに生成させるときに使われます。ある種のプロンプトを入力として与え、AIはその文の続きを生成します。
記事の生成、文章の補完、アイデアの創出など、様々なシナリオで使うことができます。 - Chat Completions APIは、会話形式のインタラクションに特化しています。複数のメッセージを入力として取り、それらの会話に対するモデルの応答を出力します。
対話型アプリケーション、カスタマーサポートボット、などに適しています。
Completions APIの例
response = openai.Completion.create(
model="text-davinci-003",
prompt="Translate the following English text to French: '{}'",
max_tokens=60
)Chat Completions APIの例
それぞれのメッセージは、”system”、”user”、 “assistant”という役割を持つことができます。
“system”:オプションで、AIアシスタントの振る舞いを制御するのに役立ちます。
“user”:ユーザーからの要求やコメントを提供
“assistant”:は前のアシスタントの応答を保持します
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "あなたは助けを提供するアシスタントです。"},
{"role": "user", "content": "2020年にワールドシリーズを勝ったのは誰ですか?"},
{"role": "assistant", "content": "2020年のワールドシリーズはロサンゼルス・ドジャースが勝ちました。"},
{"role": "user", "content": "それはどこで行われましたか?"}
]
)Chat Completions APIでは、OpenAIの最新で最も高性能なモデル(GPT-4)やコストパフォーマンスに優れたモデル(GPT-3.5-Turbo)を利用することができます。
「gpt-3.5-turbo」は「text-davinci-003」の10分の1の価格です。
model="gpt-3.5-turbo"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "フランス語でこんにちは"},
]
# APIの呼び出し
response = openai.ChatCompletion.create(
model=model,
messages=messages
)
# 結果の表示
print(response['choices'][0]['message']['content'])tiktokenを使ってトークン数を見積もる
モデルの処理能力の制約から、一度に扱うことができるトークン数にはモデルごとに上限があります。
OpenAIの「tiktokenライブラリ」はモデルにとって何トークンに相当するかを見積もることができるツールです
たとえば長い記事や論文を要約するためのモデルを使う場合などに有用です。
テキストを分割して、それぞれの部分が上限内に収まるようにするために、「tiktokenライブラリ」を使用してテキストが何トークンに相当するかを事前に計算することができます。
また、生成されるテキストの長さを制御するためにも役立ちます。
「tiktokenライブラリ」は言語モデルの利用を最適化するための重要なツールです
モデルごとのトークン数上限
トークンについて
トークンとは、言語モデルがテキストを解析するために使用する基本的な単位を指します。単語、句読点、単語の一部などが一つのトークンとして扱われます。たとえば、英語のテキスト “I love OpenAI.”は、[“I”, ” love”, ” OpenAI”, “.”]というトークンのリストに分割されます。トークン化は、自然言語処理(NLP)タスクを解析するための最初のステップです。
GPTモデルは、特定の種類のトークナイザーを使用します。
これはByte Pair Encoding(BPE)と呼ばれる手法で、一般的に言語データの圧縮や自然言語処理で使用されます。
BPEは、テキストをより小さい単位(トークン)に分割することで、テキストの長さを減らし、コンピューティングリソースを節約します。BPEは逆方向にも適用でき、元のテキストを再構成することが可能です。
トークン数の計算
tiktokenのインストール
pip install tiktoken
#すでにインストールされている場合にも最新バージョンに更新
pip install --upgrade tiktokenトークンカウンターの作成
*テキストをトークン化し、トークン数を計算するためのツール
from tiktoken import Tokenizer, TokenCounter
from tiktoken.models import Model
# モデルを作成します。ここでは、GPT-3のモデルを使用しています。
model = Model(model_name="gpt-3")
# モデルを使用して、トークンカウンターを作成します。
tokenizer = Tokenizer(model)
token_counter = TokenCounter(tokenizer)トークン数の計算
*トークンカウンターを使用して、テキストのトークン数を計算する
# 計算するテキスト。
text = "Hello, how are you?"
# トークンカウンターを使用して、テキストのトークン数を計算します。
num_tokens = token_counter.count_tokens(text)
print(f"'{text}' は {num_tokens} トークンです.")エンコーディングについて
OpenAIのGPTモデルにテキストを入力する場合、テキストはまず「トークン」という形式に変換されます。これは、テキストをモデルが理解しやすい形にするためのものです。この変換過程は「エンコーディング」と呼ばれます。
GPTモデルはテキストを直接理解するのではなく、エンコーディングされたトークンのシーケンスを理解することで、テキストの内容を把握します。
トークン数の上限は、モデルが一度に処理できるテキストの長さを決定します。このトークン数は、モデルの「コンテキストウィンドウ(コンテキスト長)」とも呼ばれます。
モデルが入力された情報を「覚えている」範囲は、そのコンテキストウィンドウ内に限定されます。
エンコーディングは、テキストをトークンに変換するための方法を指定します。
OpenAIのモデルは、テキストをトークンに変換するためのエンコーディング方法として、特に3つのエンコーディング(cl100k_base・p50k_base・ r50k_base(または gpt2))を使用します
それぞれのエンコーディングは、特定のモデル群に対応しています。
cl100k_base:GPT-4、gpt-3.5-turbo、text-embedding-ada-002といったモデルが使用します。p50k_base:Codexモデルやtext-davinci-002、text-davinci-003といったモデルが使用します。r50k_base (または gpt2):davinciといったGPT-3モデルが使用します。
特定のモデルに対応するエンコーディングを取得するためには、tiktoken.encoding_for_model()関数を使用します。
tiktoken.encoding_for_model()関数を使えば、特定のモデルに対応するエンコーディングを簡単に取得することができます。
モデルごとに異なるエンコーディングを記憶して使い分ける必要はなく、このヘルパー関数を通じて適切なエンコーディングを簡単に利用できます。
from tiktoken import encoding_for_model
encoding = encoding_for_model('gpt-3.5-turbo')